Making an RISC-V OS (Part 2): Kernel in virtual addresses
09 February 2024
See previous part on setting up the project
A quick primer on "addresses"
In kernel development simply saying "address" is ambiguous. In embedded development we often have a single address space, called "physical" addresses. On the other hand when developing normal userspace applications on mainstream desktop operating systems we also have a single address space, called "virtual" addresses.
Those two kinds of addresses look similar, but like their name hints, they are fundamentally different. Physical addresses are the bus addresses of memory, meaning the addresses that a CPU needs to write down on the memory controller bus to read the value.
Virtual addresses are an internal representation in the CPU, that get translated into physical addresses before being written to the bus.
Why would we want such a distinction in the first place? Because the virtual addresses are specific to each process. This means that we can isolate processes from each other and forbid them from accessing the physical memory in use by other processes. This also allows the kernel to delay the memory allocation to the point where the application really needs the memory address. Lastly it allows many different processes to use the same addresses, without any risks of collisions.
In a kernel we need to manipulate many address spaces. We have the knowledge of physical addresses, but we also need to have an address space for each userspace process, and we need some place to put our own code & data! When the CPU enables virtual addresses it is enabled for all memory accesses, so as a kernel we have a few choices:
- We could define the virtual addresses to be equal to the physical addresses
- We could reserve some (fixed) location in the virtual address space where our kernel always resides
The second implementation has nice properties: if we locate our kernel in the largest addresses we can share use the same kernel mappings in all our userspace processes. In addition, many userspace processes expect to be loaded in low addresses, meaning that the top 8 or 16 bits of the address should be zero.
In this blog post I'm going to explain how I implemented this in hades.
Page tables
We need to provide a mapping from virtual addresses to physical addresses, but we need to be a bit efficient to do this.
Let's say we have 1 GiB of RAM, the most naïve way would be to create a large array, where the index would be the virtual address and the value would be the physical address. This array would take up 4 GiB of RAM!
One way we could limit the size of this array would be to translate addresses by blocks. Let's say we map 128 consecutive virtual addresses to 128 consecutive physical addresses, then we need 128 times less space, only 32 MiB.
In practice the sweet spot chosen by most CPUs is 4096 bytes, known as a page. This means that in our example with 1 _GiB we only need 256 KiB, much better! The issue is that we want to handle multiple processes, let's say we want to give 1 MiB to each process, that means we could hold 1024 processes. Each process would require a different translation array, this brings us to 256 MiB of translation arrays, most of which are empty!
To solve this problem most CPUs use a structure called a "Page Table" that allows us to skip reserving memory for most unmapped pages, while still allowing translations to be pretty fast. In our example where we want to only give 1 MiB of RAM to each process we would only need 16 KiB per process, for a total of 16 MiB used to store translations.
A page table is a structure that looks a bit like this:
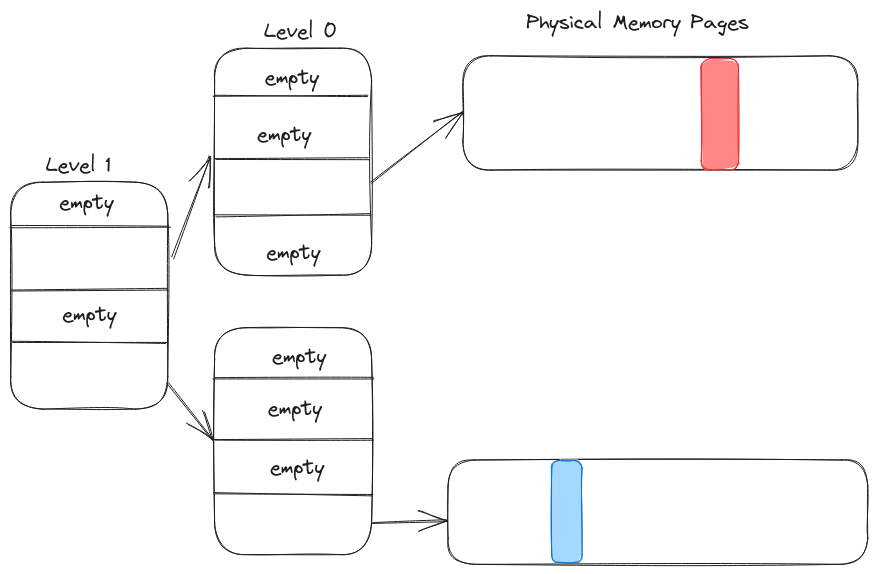
The main idea is that you take your virtual address, and split it in different parts to get the translations at the different levels of the page table.
Let's say the red region is byte 3276 in the page (or 0b110011001100).
It's corresponding virtual address in our simplified table would be 0b0110110011001100.
How did we obtain this? The virtual address is split into three parts: 0b01_10_110011001100.
The first part 01 points us to a specific Level 0 page table, by choosing the index 1 in the Level 1 list.
The second part 10 points us to a specific Physical memory page, by choosing the index 2 in the Level 0 list.
The last part 110011001100 is the offset inside the page. Because the page is the smallest granularity it is the offset in the virtual page and in the physical page.
In the same way if the offset of blue region is 0b011001100110 then its virtual address is 0b1111011001100110.
RISC-V Page Tables
Let's look specifically at RISC-V page tables. In our made up example each level only contained 4 entries, but in RISC-V 64 each level is 4096 bytes long, and each entry is 64 bytes long, meaning that we can store 512 entries in each level.
The RISC-V specification allows for different number of levels, but for our OS we are going to focus on Sv48, that has 4 levels. Virtual addresses are composed of 4 fields of 9 bits, plus a field of 12 bits for the index in the last page, giving 48 bits, hence the name.
Each entry stores a bit more than the pointer to the next entry. There are a number of flags that control the permissions of the page (readable, writable, executable). Some flags also denote the state of the page (if it was accessed, or modified).
There is also a bit to note if the page is meant for userspace or kernelspace, and another bit to note if this mapping is meant for all address spaces.
In addition, there is the context of "mega" pages. Let's look at level 0, it can contain 512 entries each pointing to a region of 4096 bytes. In some sense it points to 2 MiB of memory. "Mega" pages mean that in level 1 instead of pointing to a page of level 0, we directly point to a region of 2 MiB of physical memory. This allows to use a single level 1 mapping for a contiguous 2 MiB physical memory region, instead of 512 level 0 mappings.
By the same process we can group up 512 mega pages to create a 1 GiB "giga" page, and 512 tera pages to create a 512 GiB tera page.
For more information on RISC-V page tables you can refer to the privileged specification.
Creating a higher half kernel
As we have 48 bits of virtual addresses our address space is composed of 256 TiB. We are going to reserve the first half (all addresses under 128 TiB) for userspace, and the upper half (all addresses above 128 TiB) for the kernel.
In practice this means that all kernel addresses start with the first level set to 0b111111111, and that for every process we point the last entry of level 4 page table to our kernel level 3 page table.
We are going to reserve the last GiB of RAM for our kernel code & data segments (so that we can use a 1 GiB huge page). Then going backwards we can leave a 2 MiB gap, followed by a 2 MiB region for the kernel stack. Leaving a 2 MiB region allows guarding against malfunctions by trapping on invalid memory accesses.
Using such a mapping means that we must leave the kernel code & data segments both readable, writable and executable, which is a bit undesirable for security. We can mark the stack simply as readable & writable though.
The issue we face now is that our kernel still expects data to be reachable at physical addresses instead of the virtual addresses we want to use.
To solve this issue we are going to remove the riscv-rt dependency and instead write our own linker script to handle this!
_RAM_START = 0x80000000;
_KERNEL_START = _RAM_START + 0x2000000;
_PHYSICAL_STACK = _KERNEL_START + 16M;
_VIRTUAL_STACK = 0xffffffffbfc00000;
_STACK_LEN = 2M;
_KERNEL_CODE_VIRTUAL = 0xffffffffc0000000;
_KERNEL_VIRTUAL_RAM_START = _KERNEL_CODE_VIRTUAL + (_KERNEL_START - _RAM_START);
SECTIONS
{
. = _VIRTUAL_STACK;
.stack (NOLOAD) : AT(_PHYSICAL_STACK)
{
_estack = .;
. += _STACK_LEN;
_sstack = .;
}
_KERNEL_VIRTUAL_CODE_START = _KERNEL_VIRTUAL_RAM_START + (_boot_end - _KERNEL_START);
HIDDEN(_KERNEL_VA_CODE_OFFSET = _KERNEL_VIRTUAL_CODE_START - _boot_end);
. = _KERNEL_VIRTUAL_CODE_START;
.text : AT(ADDR(.text) - _KERNEL_VA_CODE_OFFSET) {
*(.text.abort);
*(text .text.*)
}
.rodata ALIGN(4) : AT(ADDR(.rodata) - _KERNEL_VA_CODE_OFFSET) {
*(.srodata .srodata.*);
*(.rodata .rodata.*);
/* 4-byte align the end (VMA) of this section.
This is required by LLD to ensure the LMA of the following .data
section will have the correct alignment. */
. = ALIGN(4);
}
.data ALIGN(8) : AT(ADDR(.data) - _KERNEL_VA_CODE_OFFSET) {
_sidata = LOADADDR(.data);
_sdata = .;
PROVIDE(__global_pointer$ = . + 0x800);
*(.sdata .sdata.* .sdata2 .sdata2.*);
*(.data .data.*);
. = ALIGN(8);
_edata = .;
}
.bss ALIGN(8) (NOLOAD) : AT(ADDR(.data) - _KERNEL_VA_CODE_OFFSET) {
_sbss = .;
*(.sbss .sbss.* .bss .bss.*);
. = ALIGN(8);
_ebss = .;
}
}
The main idea of this linker file is that we create sections at certain virtual memory addresses
(starting at _VIRTUAL_STACK for the stack, and _KERNEL_VIRTUAL_CODE_START for the kernel code & data).
With the : AT sections we indicate to the linker at which physical addresses we want to insert the sections.
This allows us to have an executable that is loaded into the start of the RAM, and the code expects the address to be at the end of RAM.
Though by defining our linker script like this we introduce a problem: Our boot code is going to execute without virtual enabled. So we need to add a new section:
SECTIONS
{
. = _KERNEL_START;
.physical_boot.text : {
_boot_start = .;
*(.init)
_boot_end = ABSOLUTE(.);
}
/* [... virtual memory sections] */
}
All the code that we will insert in this section will be located at a physical address. We can add all our boot procedure in the section, so that we don't have any issues.
Initializing virtual memory
When OpenSBI calls our control we are in Supervisor mode, but we don't have any virtual memory setup.
For this we need to write into the register satp the address of our 4th level page table, and the mode we want to use (Sv48).
The only issue is that we need to insert our code into the .init section, but we don't have any memory setup for the stack.
In order to control exactly what our CPU executes we are going to need to write some RISC-V assembly code.
We can start our boot.S file with the following:
.section .init
.global _start
_start:
.option push
.option norelax
1:
auipc ra, %pcrel_hi(1f)
ld ra, %pcrel_lo(1b)(ra)
jr ra
.align 3
1:
.dword _abs_start
.option pop
_abs_start:
.option norelax
.cfi_startproc
.cfi_undefined ra
/* Disable interruptions */
csrw sie, 0
csrw sip, 0
.macro LA_FAR, reg, sym
lui \reg, %hi(\sym)
addi \reg, \reg, %lo(\sym)
.endm
LA_FAR a2, _kmain
jalr zero, 0(a2)
.cfi_endproc
This relies on a global _kmain symbol defined in our main Rust code, that would be the start of the kernel in virtual memory (doing the same as our main function in the previous post).
The LA_FAR macro allows us to load addresses that are further from 12 bits than our program counter, needed as our _kmain is in virtual memory, so more than 200 TiB from our program counter.
This boot procedure is not sufficient because we don't set up any page tables in satp!
For this we are first going to create some space for the four page tables we need:
.macro DEFINE_PAGE, name
.align PAGE_SHIFT
\name:
.rep (1 << PAGE_SHIFT)
.byte 0
.endr
.endm
DEFINE_PAGE __page_kernel_level_3
DEFINE_PAGE __page_init_id_lvl2
DEFINE_PAGE __page_kernel_lvl2
DEFINE_PAGE __page_stack_lvl1
We need a root page table __page_kernel_level_3, and then we need to define three regions:
__page_kernel_lvl2for our kernel code & stack__page_stack_lvl1for our kernel stack__page_init_id_lvl2for our boot code
Indeed, when we write to satp we need to be able to continue to execute our boot code.
The __page_init_id_lvl2 is going to identity map the physical memory to virtual memory, and this will be
unmapped by our _kmain function in time.
We are going to define the following macros to create page tables:
.macro PPN, reg, pt
la \reg, \pt
srli \reg, \reg, PAGE_SHIFT
.endm
/* See _PTE_SET. va is a symbol */
.macro PTE_SET, pt, va, lvl, ppn, flags
la t1, \va
_PTE_SET \pt, \lvl, \ppn, \flags
.endm
/* See _PTE_SET. va is a far symbol */
.macro PTE_SET_FAR, pt, va, lvl, ppn, flags
LA_FAR t1, \va
_PTE_SET \pt, \lvl, \ppn, \flags
.endm
/* Clobbers: \ppn t0 t1
* va must be present in t1
* Arguments:
* pt: symbol
* va: symbol
* lvl: immediate
* ppn: register
* flags: immediate
*/
.macro _PTE_SET, pt, lvl, ppn, flags
/* extract the correct level from \va */
srli t1, t1, (12 + 9 * \lvl)
andi t1, t1, (1 << 9) - 1
slli t1, t1, 3
/* get index in the pte */
la t0, \pt
add t0, t0, t1
/* Transform the PPN into the PTE */
slli \ppn, \ppn, 10
addi \ppn, \ppn, \flags
sw \ppn, 0(t0)
.endm
With the PTE macros we can do the following to set up satp correctly:
/* Setup identity mapping */
PPN t2, __page_init_id_lvl2
PTE_SET __page_kernel_level_3, _RAM_START, 3, t2, PTE_VALID
/* 1GB identity mapping */
PPN t2, _RAM_START
PTE_SET __page_init_id_lvl2, _RAM_START, 2, t2, PTE_VALID | PTE_EXECUTE | PTE_READ | PTE_WRITE
PPN t2, __page_kernel_lvl2
PTE_SET_FAR __page_kernel_level_3, _KERNEL_CODE_VIRTUAL, 3, t2, PTE_VALID
/* 1GB kernel mapping */
PPN t2, _RAM_START
PTE_SET_FAR __page_kernel_lvl2, _KERNEL_CODE_VIRTUAL, 2, t2, PTE_VALID | PTE_EXECUTE | PTE_READ | PTE_WRITE
/* 2MB kernel stack mapping */
PPN t2, __page_stack_lvl1
PTE_SET_FAR __page_kernel_lvl2, _VIRTUAL_STACK, 2, t2, PTE_VALID
PPN t2, _PHYSICAL_STACK
PTE_SET_FAR __page_stack_lvl1, _VIRTUAL_STACK, 1, t2, PTE_VALID | PTE_READ | PTE_WRITE
li t1, 9
slli t1, t1, 60
PPN t0, __page_kernel_level_3
or t0, t0, t1
csrw satp, t0
Following this we have some remaining miscellaneous setup:
/* setup global pointer (see .data in hades.x) */
LA_FAR gp, __global_pointer$
/* setup virtual address stack (see .stack in hades.x) */
LA_FAR sp, _sstack
li x1, 0
li x2, 0
li x3, 0
li x4, 0
li x5, 0
li x6, 0
li x7, 0
li x8, 0
li x9, 0
/* skip a0,a1,a2 (x10,x11,x12) */
li x13, 0
li x14, 0
li x15, 0
li x16, 0
li x17, 0
li x18, 0
li x19, 0
li x20, 0
li x21, 0
li x22, 0
li x23, 0
li x24, 0
li x25, 0
li x26, 0
li x27, 0
li x28, 0
li x29, 0
li x30, 0
li x31, 0
With this we are finally ready to jump to _kmain!
Adaptations required for virtual memory from Part 1
In the previous post we use SBI to print a banner.
The issue is that SBI requires physical memory addresses, and we have virtual memory!
Because we defined statically our virtual to physical memory we can define a simple function to do the translation:
const RAM_START: usize = 0x80000000;
const PHYISCAL_STACK_START: usize = 0x80000000 + 0x2000000 + 16 * 1024 * 1024;
extern "C" {
#[link_name = "_KERNEL_CODE_VIRTUAL"]
static KERNEL_CODE_VIRTUAL: u8;
#[link_name = "_VIRTUAL_STACK"]
static KERNEL_STACK_VIRTUAL: u8;
}
fn virt_to_phys<T: ?Sized>(v: &T) -> usize {
let addr = v as *const T as *const () as usize;
let virtual_code_start = unsafe { &KERNEL_CODE_VIRTUAL as *const _ as usize };
let virtual_stack_start = unsafe { &KERNEL_STACK_VIRTUAL as *const _ as usize };
if addr >= virtual_code_start {
let offset = addr - virtual_code_start;
RAM_START + offset
} else if addr >= virtual_stack_start {
let offset = addr - virtual_stack_start;
PHYISCAL_STACK_START + offset
} else {
panic!("Unhandled virtual address: 0x{addr:x}")
}
}
We can then use our virt_to_phys function to translate virtual addresses to physical addresses, before passing it to SBI.
Next part is on allocating memory!